Universal eCommerce Scraper
Why building a reliable e-commerce scraper is harder than it looks — and how felid.io solves the core problems of variation extraction, JavaScript rendering, and structured product data at scale.
3/1/2026
Why We Built felid.io's Product Scraping API
For more than a decade, we've been building and operating e-commerce systems — supporting merchants with competitive intelligence, marketing automation, and data-driven decision-making.
The recurring question: What price are competitors charging right now? Is a product in stock? Are they discounting certain variants? Did a price change overnight?
We looked at existing SaaS solutions first. None had the workflow we actually needed. So we fired up the editor and started building something custom. The hardest part wasn't dashboards or alerts — it was something more fundamental: getting reliable product data from a product page.
The Problem: A Reliable Scraper That "Just Works" Didn't Exist
Most scraping tools fall into one of these categories:
Generic crawlers — good for indexing, bad for structured product data. No understanding of e-commerce product models.
HTML extraction tools — require custom selectors per site, break when layouts change, impossible to scale across thousands of stores.
LLM-based page scanning — expensive, slow, unreliable for structured extraction, and not sustainable at scale.
None of them could do the simple thing we needed: send a product URL, receive structured product data. So we built it ourselves.
The Idea Behind felid.io's E-commerce Scraper
felid.io's scraper is intentionally opinionated — focused on a single goal: extract structured product data from e-commerce product pages.
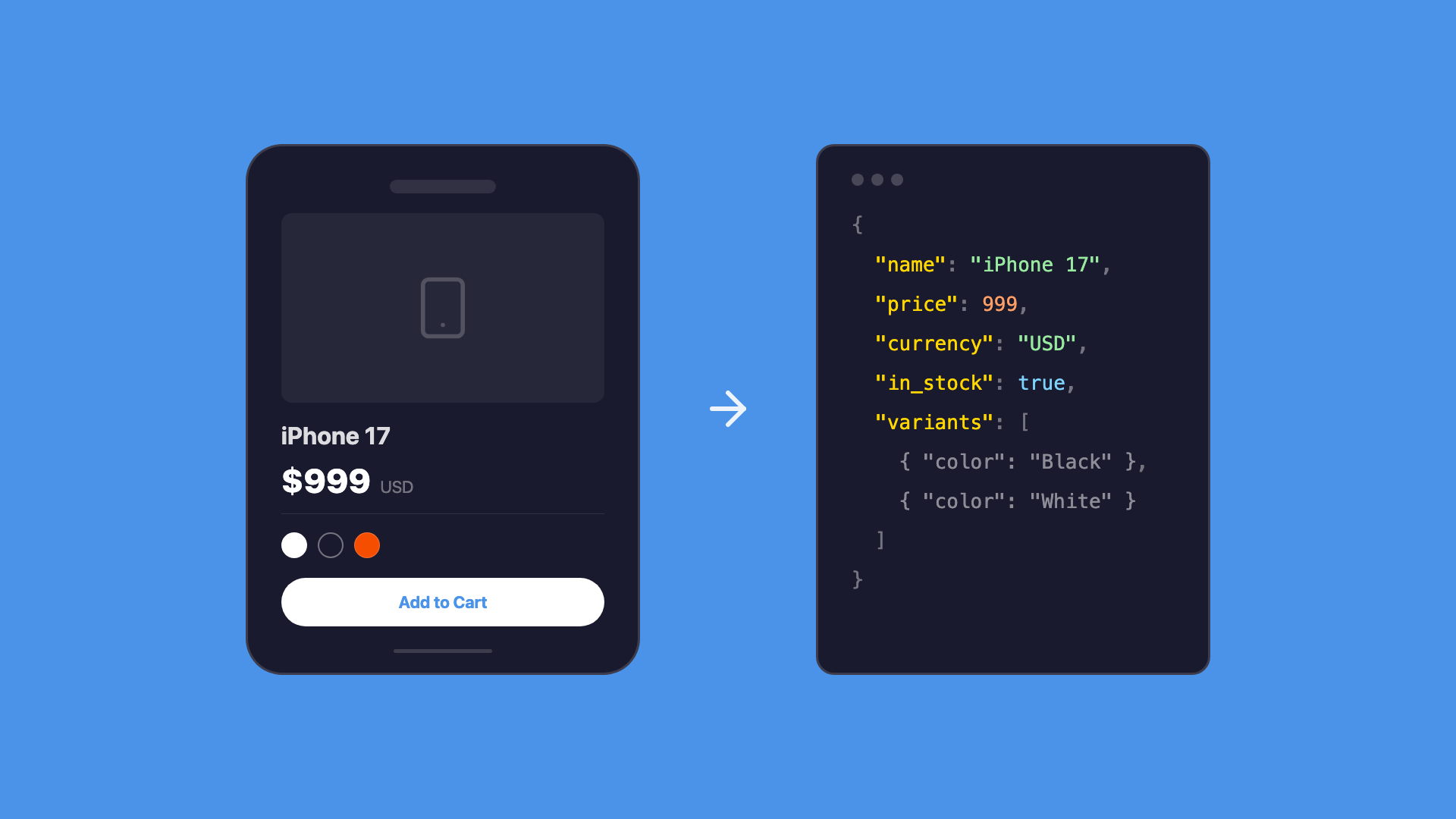
When you send a product URL to the API, you get structured JSON based on a standardized e-commerce product model:
POST /v1/products/scrape
{
"url": "https://store.com/product/iphone-17"
}
{
"productType": "VARIABLE",
"name": "iPhone 17",
"brand": "Apple",
"currency": "USD",
"variations": [
{
"attributes": { "color": "Black", "storage": "128GB" },
"price": 799,
"inStock": true
},
{
"attributes": { "color": "Blue", "storage": "256GB" },
"price": 899,
"inStock": true
}
]
}
By standardizing the output format, we turn the entire internet of e-commerce websites into one unified data source. No selectors, no custom scrapers per store. Just: URL → Structured product data.
The Hardest Problem: Extracting Product Variations
Variations are the hardest part of any e-commerce scraper.
A single product page can contain dozens of combinations — color, size, capacity, material — appearing in dropdown selectors, JavaScript-generated combinations, hidden JSON, or dynamically loaded stock states. Even modern approaches like Markdown-based page extraction completely fail here. Markdown works for static content, but product variations require interpreting UI selectors, understanding attribute relationships, and resolving variation-specific pricing and stock. Even AI models often struggle with this reliably.
That's why felid.io's scraper includes specialized logic designed specifically for variation discovery and normalization.
JavaScript Rendering, Anti-Bot Handling, and Retry Logic
Many product pages rely on JavaScript frameworks — React, Vue, Next.js, Shopify Hydrogen. Without rendering, critical product data may not exist in the HTML.
felid.io handles all of this transparently:
- JavaScript rendering — pages are rendered when necessary
- Anti-bot protection — detection and mitigation for common blocking mechanisms
- Retry logic — automatic retries using different strategies on failure
From the API user's perspective: send a URL, receive structured product data.
Reliability First, Cost Second
Many scraping systems rely heavily on AI to interpret pages. This comes with real downsides — high token costs, slower processing, occasional hallucinations, and unpredictable outputs.
felid.io takes a different approach. We continuously optimize to avoid AI extraction whenever possible, preferring deterministic methods: structured data parsing, DOM pattern analysis, platform-specific heuristics, and JavaScript state inspection. AI is used only when necessary. This hybrid approach improves both accuracy and cost efficiency.
AI Generation vs. AI Analysis
AI generation and AI analysis are fundamentally different problems.
When AI generates content, "good enough" is fine. But when AI analyzes structured data, even a single hallucinated value can break an entire system. Imagine a price monitoring pipeline where one hallucinated value reports $9 instead of $999 — alerts fire incorrectly, dashboards become unreliable, automation breaks.
For data extraction, precision matters more than creativity. That's why felid.io uses an opinionated workflow and data structure rather than relying on AI interpretation.
Real-World Use Cases
Building a Competitor Price Monitor
Identify competitor products, store their URLs, and run the scraper on a schedule — daily, hourly, or as needed. When a competitor drops a price or goes out of stock, your system knows immediately.
felid.io also offers a dedicated monitoring service under the /monitor endpoint — a managed solution that handles scheduling, change detection, and alerting. Instead of running the scraper yourself on a cron job, register the URLs you care about and let the monitoring service do the rest.
Importing a Manufacturer's Catalog Into Your Store
Iterate over product URLs from a manufacturer's catalog and pull back structured product data: names, descriptions, prices, variants, and stock status. Because the output is normalized, importing into WooCommerce, Shopify, or any other platform is straightforward — no brittle HTML parsing, no custom scraper per category.
Building a Price Comparison Website
Collect structured product data from dozens or hundreds of retailers for the same product — prices, stock status, variation availability — on a continuous schedule. Because the output follows a standardized product model, matching the same product across different stores becomes a data problem, not a scraping problem.
Showing Retailers on a Manufacturer's Product Page
Manufacturers can register retailer product URLs, run the scraper on a schedule, and surface live pricing and stock status directly on their own product pages. When a retailer promotes a product, drops a price, or goes out of stock on a specific variant, the manufacturer's site reflects it in real time — no retailer integrations to negotiate, no custom data feeds to maintain.